Opening Excel files
Usually, rectangular data matrices of variables by samples, or samples by variables, will initially have been entered into Excel. For entry to PRIMER, these should have different data arrays (e.g. abundance, biomass, environmental variables etc.) in different sheets – though they can be in the same Excel file – and will need to be read in one sheet at a time. The data format is simple but specific and must be adhered to. For the above Ekofisk counts, an Excel file would have been:
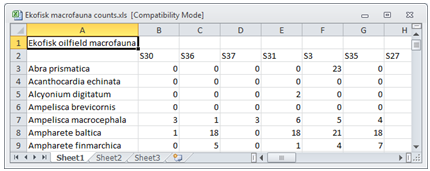
If referring to the same set of sample locations/times/treatments/replicates, different biotic and abiotic arrays should have the same (unique) sample labels over the different sheets; the samples can then be matched. The label would helpfully be a combination of the particular location/time/ treatment/replicate alphanumeric codes, though it could be a simple integer code (1, 2, 3, …). Either way, the place to identify the different factors (location, time etc – see Section 2) is not as multiple heading rows at the top of the matrix (only one row of sample labels is allowed) but at the bottom of the array, separated from the data by a blank row. The data array can be entered as the transpose of that shown above (samples as rows rather than columns) but the same principle applies – any factors are placed to the right of the data separated by a blank column (in practice, a blank column label is sufficient to make PRIMER believe that the data has finished and the factors started, so you must avoid using a blank sample label). An example of the environmental data for the Ekofisk study, in this transposed format, is now used to step through the input options.